

资深天翼
萌新最近想学关于字符串的算法,AC自动机,但学这个之前必须要会KMP和trie,求大佬推荐一篇好的文章(在百度上没找到合适的)
当然也可以自己阐述这两种算法。


修练者
前言
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法)。KMP算法的关键是利用匹配失败后的信息(已经匹配的部分中的对称信息),尽量减少模式串(待搜索词)与文本串的匹配次数以达到快速匹配的目的。具体实现就是实现一个next()函数,该函数本身包含了模式串的局部匹配信息。
<C/C++算法>字符串匹配---KMP算法
2015年10月14日 19:14:32
阅读数:8559
前言
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法)。KMP算法的关键是利用匹配失败后的信息(已经匹配的部分中的对称信息),尽量减少模式串(待搜索词)与文本串的匹配次数以达到快速匹配的目的。具体实现就是实现一个next()函数,该函数本身包含了模式串的局部匹配信息。
一,kmp算法的原理:
字符串匹配是计算机的基本任务之一。它所执行的任务就是在一个文本(较长的字符串)中查找是否包含着当前指定的模式字符串(较短的字符串),并找到其位置,这就是字符串匹配问题。
注:在算法导论里面待搜索的词叫“模式”字符串,并用P来表示,本文有的地方叫他“待搜索词”。如无特殊说明数组下标以0为起始。
举例来说,有一个长字符串"BBC ABCDAB ABCDABCDABDE"(即文本串),我想知道里面是否包含另一个模式字符串"ABCDABD",它的位置在哪呢?
1,朴素匹配算法过程:
1).
首先,长字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2).
怎么做到这一点呢(如何跳过不必要的位置在不匹配时)?可以针对搜索词,算出一张模式字符串的前缀函数表。这张表是如何产生的,后面再介绍,这里只要知道就可以了。
3).
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查模式串的《前缀函数表》可知,其前缀(即ABCDAB)中的最后一个匹配字符B的位置对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数(直接将前面的对称信息调到后面的对称位置,跳过一些不必要的位置):
移动位数 = 已匹配的字符数 - 当前已匹配字符串的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位(之所以移动4,是因为搜索词的已匹配的前缀串“ABCDA
B"已经匹配的部分。KMP算法的想法是,设法利用这个搜索词的子串(就是搜索词的某个前缀)的已知对称值,注意这里的对称非中心对称,而是基于搜索词的某一个前缀的对称信息,在不匹配的时候跳过一些不必要的位置来加速匹配速度,这样就提高了效率。
2).
怎么做到这一点呢(如何跳过不必要的位置在不匹配时)?可以针对搜索词,算出一张模式字符串的前缀函数表。这张表是如何产生的,后面再介绍,这里只要知道就可以了。
3).
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查模式串的《前缀函数表》可知,其前缀(即ABCDAB)中的最后一个匹配字符B的位置对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数(直接将前面的对称信息调到后面的对称位置,跳过一些不必要的位置):
移动位数 = 已匹配的字符数 - 当前已匹配字符串的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位(之所以移动4,是因为搜索词的已匹配的前缀串“ABCDAB”的部分匹配值为2,即有“AB”对称,因为当前已匹配字符串的“AB”始终要找到下一个“AB”的开始位置,而这个开始位置恰好就在本字符串中的后缀中,所以直接移动4,我们可以最大减少匹配次数)。
4).
因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
5).
因为空格与A不匹配,继续后移一位。
6).
逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
7).
逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
3,关于前缀函数表
1)前缀和后缀
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
2).前缀函数表的产生
"前缀函数"的对称值(也叫部分匹配值)就是模式串的对应前缀中的"前缀"和"后缀"的最长的共有元素的长度(实质是最大对称程度)。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2(“AB”是其最大对称串,长度为2);
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
A,首相要搞清楚的是它是模式字符串的所有前缀产生的一张表,保存的值表征了最大对称度,我们一般用next数组来保存其某个前缀的对称值,例如next[6]=2,代表的就是模式串的某个有6个字符的前缀“ABCDAB”,这个前缀的对称度就是2,即“AB”是对称的。
B,模式串的某前缀的对称值的实质是,有时候,搜索词已经部分匹配了(一定是某个前缀),其某个前缀(已经匹配部分)的头部和尾部会有重复。比如,"ABCDAB"之中前缀有"AB",后缀也有"AB",那么它的"前缀函数对称值"就是2("AB"的长度,且“AB”是"ABCDAB"所有前缀和后缀中的最长公有元素)。搜索词移动的时候,第一个"AB"向后移动4位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置,在这个新的位置我们跳过了不必要的比较位置,并且直接就有“AB”匹配。
二,前缀函数表实现原理
通过上文完全可以对kmp算法的原理有个清晰的了解,那么下一步就是编程实现了,其中最重要的就是如何根据待匹配的模式字符串求出其所有前缀函数表中的最大对称值,在下文中我们将其存储在next数组中。
1,编程策略:
1,编程策略:
1)、当前字符的前面所有字符的对称程度为0的时候,只要将当前字符与前面这个子串的第一个字符进行比较。这个很好理解啊,前面所有字符串的对称值都是0,说明都不对称了,如果多加了一个字符,要对称的话只能是当前字符和前面字符串的第一个字符对称。比如“ABCDA”这个里面"ABCD"的最大对称值是0,那么后面的A的对称程度只需要看它是不是等于前面字符串的第一个字符A相等,如果相等就增加1,如果不相等那就保持不变,显然还是为0。
2)、按照这个推理,我们就可以总结一个规律,不仅前面是0呀,如果前面字符串的的最大对称值是1(k),那么我们就把当前字符与前面字符串的第二(k)个字符即P[1](P[k])进行比较,因为前面的是1(k),说明前面的字符已经和第一(k)个字符相等了,如果这个又与第二(k+1)个相等了,说明对称程度就是2(k+1)了。有两(k+1)个字符对称了。比如上面“ABCDA”的最大对称值是1,说明它只和第一个A对称了,接着我们就把下一个字符“B”与P[1](即第二个字符)比较,又相等,自然对称程度就累加了,就是2了。
但是如果不相等呢?那么这个对称值显然要减少,并且我们只能到前面去寻找对称值,而在找的过程我们同时也利用前缀函数表快速搜索找到与当前字符匹配的位置。比如假设是“(AGCTAGC)(AGCTAGC)T”(请无视字符串中的括号,只为方便看出对称),显然最后一个T的前一个位置的对称度是7,说明T的前一个位置的7个字符的后缀必与7个字符的前缀相等,然而T!=P[7],说明T位置的对称度只能是比7小的长度的前缀,所以递减k值,递减为多少呢?当前字符前一个位置的对称度为k=next[13]=7,显然必须以7为基准减少,即在前缀长度为7以内的范围重新寻找以T结尾的前缀,所以k=next[6],再接着判断是否相等,
3)、按照上面的推理,我们总是在找当前字符P[q](q为遍历到的位置下标,见下面程序)通过其前一个位置的对称值判断是否与P[k]相等,如果相等,那么加,如果不相等,那么就减少k值,重新寻找与与P[q]相等的元素位置.
2,参考代码:
1 void MakeNext(const char P[],int next[])
2 {
3 int k;//k:最大对称长度
4 int m = strlen(P);//模版字符串长度
5 next[0] = 0;//模版字符串的第一个字符的最大对称值必为0
6 for (int q = 1,k = 0; q < m; ++q)//for循环,从第二个字符开始,依次计算每一个字符对应的next值
7 {//在前一个位置的k不为0,但是却不相等,那么减少k,重新寻找与P[q]相等的位置,让下面的if来增加k
8 while(k > 0 && P[q] != P[k])//
9 k = next[k-1]; //while循环是整段代码的精髓所在,
10 if (P[q] == P[k])//如果相等,那么最大相同前后缀长度加1
11 k++;//增加k的唯一方式
12 next[q] = k;
13 }
14 }
3,代码解释:
现在我着重讲解一下while循环所做的工作:
- 已知前一个位置的最大相同前后缀长度为k,且k>0,即P[0]···P[k-1];
- 此时比较第k项P[k]与P[q],如图1所示
- 如果P[K]等于P[q],那么很简单跳出while循环;
- 如果不等呢?那么我们应该利用已经得到的next[0]···next[k-1]来求P[0]···P[k-1]这个前缀中最大相同前后缀。为什么要求P[0]···P[k-1]的最大相同前后缀呢?为什么呢? 原因在于P[k]已经和P[q]失配了,而且P[q-k] ··· P[q-1]又与P[0] ···P[k-1]相同,看来P[0]···P[k-1]这么长的子串是用不了了,那么我要找个同样也是P[0]打头、P[k-1]结尾的子串即P[0]···P[j-1](j==next[k-1]),看看它的下一项P[j]是否能和P[q]匹配。


高级天翼
《字符串匹配的KMP算法》这本书上有


缔造者之神
1
修练者
望采纳!!!



修练者
Trie树(c++实现)
技术mix呢 2017-11-09 18:02:00 浏览148 评论0
摘要: 原理 先看个例子,存储字符串abc、ab、abm、abcde、pm可以利用以下方式存储 上边就是Trie树的基本原理:利用字串的公共前缀来节省存储空间,最大限度的减少无谓的字串比较。 应用 Trie树又称单词查找树,典型的应用是用于统计,排序和保存大量的字符串(不仅用于字符串),所以经常被搜索引擎系统用于文本词频的统计。
原理
先看个例子,存储字符串abc、ab、abm、abcde、pm可以利用以下方式存储
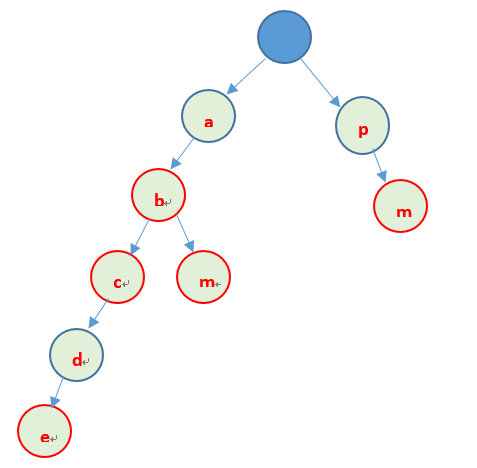
上边就是Trie树的基本原理:利用字串的公共前缀来节省存储空间,最大限度的减少无谓的字串比较。
应用
Trie树又称单词查找树,典型的应用是用于统计,排序和保存大量的字符串(不仅用于字符串),所以经常被搜索引擎系统用于文本词频的统计。
设计
trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
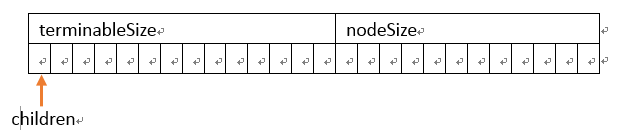
结点可以设计成这样:

class trieNode
{
public:
trieNode() : terminableSize(0), nodeSize(0) { for(int i = 0; i < Size; ++i) children[i] = NULL; }
~trieNode()
{
for(int i = 0; i < Size; ++i)
{
delete children[i];
children[i] = NULL;
}
}
public:
int terminableSize; //存储以此结点为结尾的字串的个数
int nodeSize; //记录此结点孩子的个数
trieNode* children[Size]; //该数组记录指向孩子的指针
};
图示
树设计成这样:
template<int Size, class Type>
class trie
{
public:
typedef trieNode<Size> Node;
typedef trieNode<Size>* pNode;
trie() : root(new Node) {}
template<class Iterator>
void insert(Iterator beg, Iterator end);
void insert(const char *str);
template<class Iterator>
bool find(Iterator beg, Iterator end);
bool find(const char *str);
template<class Iterator>
bool downNodeAlone(Iterator beg);
template<class Iterator>
bool erase(Iterator beg, Iterator end);
bool erase(const char *str);
int sizeAll(pNode);
int sizeNoneRedundant(pNode);
public:
pNode root;
private:
Type index;
};
index字串索引利用(char % 26) 得到,这样'a' % 26 = 19, 'b' % 26 = 20
实现
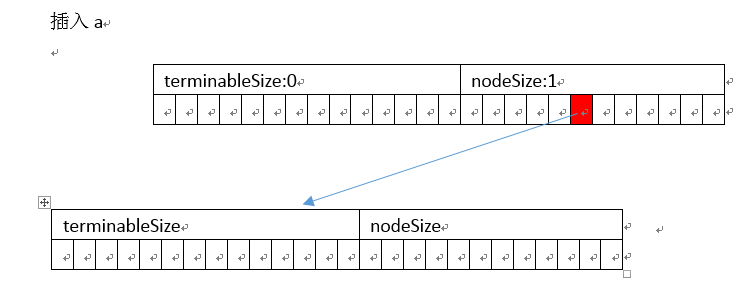
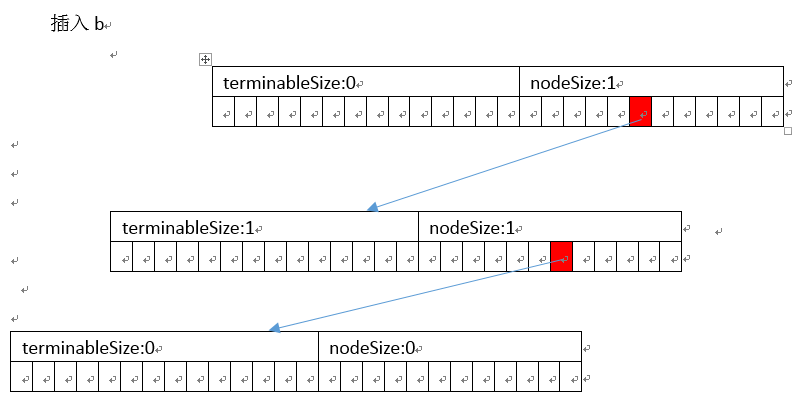
插入
以插入abc、ab为例
 ]
]
删除
删除结点,首先查找此字串是否在树中,如果在树中,再查找此结点以下的部分是不是都是只有一个孩子,并且每个结点只有叶子结点是结束结点,如果不是继续往下重复上边过程。
统计字串个数
分两种情况
- 计算重复的字串的个数:是结束结点,此时加的是terminabel的个数
- 计算不重复的字串的个数:是结束结点,此时加的是1(当terminabel>0)的个数
参考代码
#include <iostream>
#include <cstring>
using namespace std;
template<int Size>
class trieNode
{
public:
trieNode() : terminableSize(0), nodeSize(0) { for(int i = 0; i < Size; ++i) children[i] = NULL; }
~trieNode()
{
for(int i = 0; i < Size; ++i)
{
delete children[i];
children[i] = NULL;
}
}
public:
int terminableSize;
int nodeSize;
trieNode* children[Size];
};
template<int Size, class Type>
class trie
{
public:
typedef trieNode<Size> Node;
typedef trieNode<Size>* pNode;
trie() : root(new Node) {}
template<class Iterator>
void insert(Iterator beg, Iterator end);
void insert(const char *str);
template<class Iterator>
bool find(Iterator beg, Iterator end);
bool find(const char *str);
template<class Iterator>
bool downNodeAlone(Iterator beg);
template<class Iterator>
bool erase(Iterator beg, Iterator end);
bool erase(const char *str);
int sizeAll(pNode);
int sizeNoneRedundant(pNode);
public:
pNode root;
private:
Type index;
};
template<int Size, class Type>
template<class Iterator>
void trie<Size, Type>::insert(Iterator beg, Iterator end)
{
pNode cur = root;
pNode pre;
for(; beg != end; ++beg)
{
if(!cur->children[index[*beg]])
{
cur->children[index[*beg]] = new(Node);
++cur->nodeSize;
}
pre = cur;
cur = cur->children[index[*beg]];
}
++pre->terminableSize;
}
template<int Size, class Type>
void trie<Size, Type>::insert(const char *str)
{
return insert(str, str + strlen(str));
}
template<int Size, class Type>
template<class Iterator>
bool trie<Size, Type>::find(Iterator beg, Iterator end)
{
pNode cur = root;
pNode pre;
for(; beg != end; ++beg)
{
if(!cur->children[index[*beg]])
{
return false;
break;
}
pre = cur;
cur = cur->children[index[*beg]];
}
if(pre->terminableSize > 0)
return true;
return false;
}
template<int Size, class Type>
bool trie<Size, Type>::find(const char *str)
{
return find(str, str + strlen(str));
}
template<int Size, class Type>
template<class Iterator>
bool trie<Size, Type>::downNodeAlone(Iterator beg)
{
pNode cur = root;
int terminableSum = 0;
while(cur->nodeSize != 0)
{
terminableSum += cur->terminableSize;
if(cur->nodeSize > 1)
return false;
else //cur->nodeSize = 1
{
for(int i = 0; i < Size; ++i)
{
if(cur->children[i])
cur = cur->children[i];
}
}
}
if(terminableSum == 1)
return true;
return false;
}
template<int Size, class Type>
template<class Iterator>
bool trie<Size, Type>::erase(Iterator beg, Iterator end)
{
if(find(beg, end))
{
pNode cur = root;
pNode pre;
for(; beg != end; ++beg)
{
if(downNodeAlone(cur))
{
delete cur;
return true;
}
pre = cur;
cur = cur->children[index[*beg]];
}
if(pre->terminableSize > 0)
--pre->terminableSize;
return true;
}
return false;
}
template<int Size, class Type>
bool trie<Size, Type>::erase(const char *str)
{
if(find(str))
{
erase(str, str + strlen(str));
return true;
}
return false;
}
template<int Size, class Type>
int trie<Size, Type>::sizeAll(pNode ptr)
{
if(ptr == NULL)
return 0;
int rev = ptr->terminableSize;
for(int i = 0; i < Size; ++i)
rev += sizeAll(ptr->children[i]);
return rev;
}
template<int Size, class Type>
int trie<Size, Type>::sizeNoneRedundant(pNode ptr)
{
if(ptr == NULL)
return 0;
int rev = 0;
if(ptr->terminableSize > 0)
rev = 1;
if(ptr->nodeSize != 0)
{
for(int i = 0; i < Size; ++i)
rev += sizeNoneRedundant(ptr->children[i]);
}
return rev;
}
template<int Size>
class Index
{
public:
int operator[](char vchar)
{ return vchar % Size; }
};
int main()
{
trie<26, Index<26> > t;
t.insert("hello");
t.insert("hello");
t.insert("h");
t.insert("h");
t.insert("he");
t.insert("hel");
cout << "SizeALL:" << t.sizeAll(t.root) << endl;
cout << "SizeALL:" << t.sizeNoneRedundant(t.root) << endl;
t.erase("h");
cout << "SizeALL:" << t.sizeAll(t.root) << endl;
cout << "SizeALL:" << t.sizeNoneRedundant(t.root) << endl;
}
结果

技术实现细节
1. 对树的删除,并不是树销毁结点,而是通过结点自身的析构函数实现
2. 模版类、模版函数、非类型模版可以参考:http://www.cnblogs.com/kaituorensheng/p/3601495.html
3. 字母的存储并不是存储的字母,而是存储的位置,如果该位置的指针为空,则说明此处没有字母;反之有字母。
4. terminableNum存储以此结点为结束结点的个数,这样可以避免删除时,不知道是否有多个相同字符串的情况。
修练者
望采纳!!!
修练者
字符串匹配KMP算法C++代码实现
2016年10月30日 10:21:03
阅读数:1813
看到了一篇关于《字符串匹配的KMP算法》(见下文)的介绍,地址:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html,这篇博客对KMP算法的解释很清晰,但缺点是没有代码的实现。所以本人根据这位大神的思路写了一下算法的C++实现。
C++代码如下:
-
#include <iostream> -
#include<string.h> -
using namespace std; -
int kmp(const char *text, const char *find) -
{ -
if (text == '\0' || find == '\0') -
return -1; -
int find_len = strlen(find); -
int text_len = strlen(text); -
if (text_len < find_len) -
return -1; -
int map[find_len]; -
memset(map, 0, find_len*sizeof(int)); -
map[0] = 0; -
map[1] = 0; -
int i = 2; -
int j = 0; -
//计算《部分匹配表》 map -
for (i=2; i<=find_len; i++) -
{ -
while (1) -
{ -
if (find[i-1] == find[j]) -
{ -
j++; -
map[i-1]=j; -
break; -
} -
else -
{ -
if (j == 0) -
{ -
map[i] = 0; -
break; -
} -
j = map[j]; -
} -
} -
} -
/* for(int m=0; m<find_len; ++m) -
{ -
cout << map[m]<<endl; -
}*/ -
i = 0; -
j = 0; -
//KMP算法实现 -
for (i=0; i<text_len;) -
{ -
if (text[i] == find[j]) -
{ -
i++; -
j++; -
continue; -
} -
if (j == (find_len)) -
return i-j; -
else -
{ -
if (j == 0) -
i++; -
else -
j = map[j-1]; -
} -
} -
return -1; -
} -
int main() -
{ -
char* str1="BBC ABCDAB ABCDABCDABDE"; -
char * str2 ="ABCDABD"; -
int temp =kmp(str1, str2); -
cout << temp<<endl; -
return 0; -
}
转自《字符串匹配的KMP算法》
举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?

许多算法可以完成这个任务,Knuth-Morris-Pratt算法(简称KMP)是最常用的之一。它以三个发明者命名,起头的那个K就是著名科学家Donald Knuth。

这种算法不太容易理解,网上有很多解释,但读起来都很费劲。直到读到Jake Boxer的文章,我才真正理解这种算法。下面,我用自己的语言,试图写一篇比较好懂的KMP算法解释。
1.

首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.

因为B与A不匹配,搜索词再往后移。
3.

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。
7.
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.
怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
9.
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。
10.
因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
11.
因为空格与A不匹配,继续后移一位。
12.

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.
逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
14.
下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
15.
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
16.
"部分匹配"的实质是,有时候,字符串头部和尾部会有重复。比如,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候,第一个"AB"向后移动4位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置。
(完)


高级守护
ABCDEFGHIJKIMNOPQRSTUVWXYZ

资深天翼
1


缔造者
1
