

初级天翼
下周就要学搜索了,听邢老师说搜索要用递归
不得不说,我的递归学的真心不行,之前问的汉诺塔也是递归的题
有谁比较熟悉递归的该我讲一讲呗,不要网址

初级天翼
你好,我们是一个老师教的,这个我相信你也看过吧:

你可以按照这上面来复习,效果会好,然后再找到对应讲义复习,递归应该就差不多了吧
PS:上面怎么都是百度大哥的回答?


高级天翼
https://judge.codingtang.com/recording/2595/
嘿嘿,你不会没有150都吧


高级光能
几乎每一本C 语言基础的书都讲到了函数递归的问题,但是初学者仍然容易在这个地方犯错误。先看看下面的例子:
void fun(int i)
{
if (i>0)
{
fun(i/2);
}
printf("%d\n",i);
}
intmain()
{
fun(10);
return 0;
}
问:输出结果是什么?
这是我上课时,一个学生问我的问题。他不明白为什么输出的结果会是这样:
0
1
2
5
10
他认为应该输出0。因为当i 小于或等于0 时递归调用结束,然后执行printf 函数打印i 的值。
这就是典型的没明白什么是递归。其实很简单,printf("%d\n",i);语句是fun 函数的一部分,肯定执行一次fun 函数,就要打印一行。怎么可能只打印一次呢?关键就是不明白怎么展开递归函数。展开过程如下:
void fun(int i)
{
if (i>0)
{
//fun(i/2);
if(i/2>0)
{
if(i/4>0)
{
…
}
printf("%d\n",i/4);
}
printf("%d\n",i/2);
}
printf("%d\n",i);
}
这样一展开,是不是清晰多了?其实递归本身并没有什么难处,关键是其展开过程别弄错了。
二、不使用任何变量编写strlen 函数
看到这里,也许有人会说,strlen 函数这么简单,有什么好讨论的。是的,我相信你能熟练应用这个函数,也相信你能轻易的写出这个函数。但是如果我把要求提高一些呢:
不允许调用库函数,也不允许使用任何全局或局部变量编写intmy_strlen (char *strDest);似乎问题就没有那么简单了吧?这个问题曾经在网络上讨论的比较热烈,我几乎是全程“观战”,差点也忍不住手痒了。不过因为我的解决办法在我看到帖子时已经有人提出了,所以作罢。
解决这个问题的办法由好几种,比如嵌套有编语言。因为嵌套汇编一般只在嵌入式底层开发中用到,所以本书就不打算讨论C 语言嵌套汇编的知识了。有兴趣的读者,可以查找相关资料。
也许有的读者想到了用递归函数来解决这个问题。是的,你应该想得到,因为我把这个问题放在讲解函数递归的时候讨论。既然已经有了思路,这个问题就很简单了。代码如下:
intmy_strlen( const char* strDest )
{
assert(NULL != strDest);
if ('\0' == *strDest)
{
return 0;
}
else
{
return (1 + my_strlen(++strDest));
}
}
第一步:用assert 宏做入口校验。
第二步:确定参数传递过来的地址上的内存存储的是否为'\0'。如果是,表明这是一个空字符串,或者是字符串的结束标志。
第三步:如果参数传递过来的地址上的内存不为'\0',则说明这个地址上的内存上存储的是一个字符。既然这个地址上存储了一个字符,那就计数为1,然后将地址加1 个char类型元素的大小,然后再调用函数本身。如此循环,当地址加到字符串的结束标志符'\0'时,递归停止。
当然,同样是利用递归,还有人写出了更加简洁的代码:
intmy_strlen( const char* strDest )
{
return *strDest?1+strlen(strDest+1):0;
}
这里很巧妙的利用了问号表达式,但是没有做参数入口校验,同时用*strDest 来代替('\0'== *strDest)也不是很好。所以,这种写法虽然很简洁,但不符合我们前面所讲的编码规范。可以改写一下:
intmy_strlen( const char* strDest )
{
assert(NULL != strDest);
return ('\0' != *strDest)?(1+my_strlen(strDest+1)):0;
}
上面的问题利用函数递归的特性就轻易的搞定了,也就是说每调用一遍my_strlen 函数,其实只判断了一个字节上的内容。但是,如果传入的字符串很长的话,就需要连续多次函数调用,而函数调用的开销比循环来说要大得多,所以,递归的效率很低,递归的深度太大甚至可能出现错误(比如栈溢出)。所以,平时写代码,不到万不得已,尽量不要用递归。即便是要用递归,也要注意递归的层次不要太深,防止出现栈溢出的错误;同时递归的停止条件一定要正确,否则,递归可能没完没了。
初级天翼
你是邢老师班的?我也是,我是算法2班
递归这方面我学的真的还不错,但是不知道你要哪方面的,比如说换瓶子?汉诺塔?递推转递归?
你告诉我范围
还有一种就是你可以翻翻之前的讲义(PS:我们也是要学搜索与回溯了)

高级光能
递归函数:
编程语言中,函数Func(Type a,……)直接或间接调用函数本身,则该函数称为递归函数。递归函数不能定义为内联函数。
在数学上,关于递归函数的定义如下:对于某一函数f(x),其定义域是集合A,那么若对于A集合中的某一个值X0,其函数值f(x0)由f(f(x0))决定,那么就称f(x)为递归函数。
定义:
一种计算过程,如果其中每一步都要用到前一步或前几步的结果,称为递归的。用递归过程定义的函数,称为递归函数,例如连加、连乘及阶乘等。凡是递归的函数,都是可计算的,即能行的 .
古典递归函数,是一种定义在自然数集合上的函数,它的未知值往往要通过有限次运算回归到已知值来求出,故称为“递归”。它是古典递归函数论的研究对象.
在数理逻辑和计算机科学中,递归函数或μ-递归函数是一类从自然数到自然数的函数,它是在某种直觉意义上是"可计算的" 。事实上,在可计算性理论中证明了递归函数精确的是图灵机的可计算函数。递归函数有关于原始递归函数,并且它们的归纳定义(见下)建造在原始递归函数之上。但是,不是所有递归函数都是原始递归函数 — 最著名的这种函数是阿克曼函数。
其他等价的函数类是λ-递归函数和马尔可夫算法可计算的函数。
一个直接的例子
1
2
3
4
5
6
7
8
9
//代码1
void func()
{
//...
if(...)
func();
else
//...
}
条件
一个含直接或间接调用本函数语句的函数被称之为递归函数,在上面的例子中能够看出,它必须满足以下两个条件:
1) 在每一次调用自己时,必须是(在某种意义上)更接近于解;
2) 必须有一个终止处理或计算的准则。
例如:
梵塔的递归函数
1
2
3
4
5
6
7
8
9
10
11
12
//C
void hanoi(int n,char x,char y,char z)
{
if(n==1)
move(x,1,z);
else
{
hanoi(n-1,x,z,y);
move(x,n,z);
hanoi(n-1,y,x,z);
}
}
阶乘的递归函数,公式如下:
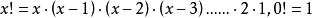
1
2
3
4
5
6
7
8
//C++
int Factorial(int n)
{
if(n==0||n==1)
return 1;
else
return n * Factorial(n-1)
}
计算
函数的概念是一个很一般的概念。在定义函数时,不一定要具体给出通过自变量求函数值的方法。因此,可将函数分成两类,一类是所谓能行可计算函数,另一类是非能行可计算的函数。这前一种函数无论在理论上或在实际上都是非常重要的,因此人们便试图给它们以精确的数学刻画。递归函数便是许多这种刻画中的一种 [2] 。
我们以下考虑的函数都是从自然数到自然数的函数。
我们先定义几个初等函数
(1)零函数 Z(x)=0;
(2)后继函数 S(x)=x+1;
(3)广义幺函数 U1n(x1,…xn)=xi;
显然,上面这些函数都是能行可计算的。
再介绍几个将函数变换为函数的算子。
(1)复合算子 设f是n元函数,g1…gn是m元函数,复合算子将f,g1…gn变换成为如下的m元函数h:
h(x1…xm)=f1g1(x1,…xm),…gn(x1,…xm))
(2)递归算子 设f是n元函数 (≥0),g是n+2元函数,递归算子将f,g变换成满足下列条件的h+1元函数h:
h(x1,…,xn,0)=f(x1,…xn)
h(x1,…xn,y+1)=g(x1,…xn,y,h(x1,…xn))
(3)μ一算子,设f是n+1元函数,如果存在y,使f(x1,…xn,y)=0,我们以μyf(x1…xny)表示这样的y中的最小者,如果使f(x1…xny)=0的y不存在,我们说μyf(x1,…xny)无定义。μ-算子将n+1元函数f变换成下面的几元函数h
h(x1,…xn)=μyf(x1…xny)
注意,μ算子可以将一个全函数变换成一个部分函数(即在自然数的某个子集上有定义的函数)。
可以看出,上述所有算子都是将能行可计算函数变换为能行可计算函数。
所谓递归函数类便是包含零函数、广义幺函数,并在复合算子、递归算子,μ-算子下封闲的最小函数类。
容易相信,任何递归函数都是能行可计算的。反过来,是否存在直观上能行可计算的,但不是递归的函数呢?人们直到现在还没有发现这样的函数。相反,人们证明了,现已遇到的直观上能行可计算的函数都是递归函数。进一步,人们还证明了,递归函数类与其他的一些刻画能行可计算函数的方法产生的函数类是完全一致的,这些事实促使车尔赤(Church)提出了他的著名的论点:
递归函数类与直观能行可计算函数类是重合的。
这个论点已被大多数递归论学者所接受。
例子
【pascal语言】
1
2
3
4
5
6
//使用VB代码格式,实际为Pascal
functiondo(x:integer);
begin
ifx<=1thenexit(0)
elseifx>1thenexit(do(x-1)+10)
end;
//度娘:“问我”!


中级光能
1、递归,快速排序,八皇后
2、线性DP,区间型DP(能量项链),
背包问题(01,多重、满箱问题,完全背包);
3、字符串专题、高精度的+-*。
二、递归的使用
函数被其他的函数或者主函数调用。
递归自杀式的,自己调用自己。
(同理,相同的道理)
- 递归出口,问题简单化,树立远大的理想。
- 调用自身的表达式(自杀的表达式)
- 有条件地降阶(向出口去逼近)
案例1:n!=1*2*3*..*n;
s=s*i;
5!=1*2*3*4*5
int jie(int n)//任务给我一个n返回 n!
{
int i,s=1; //1*2*3..*n s=s*i
for (i=1;i<=n;i++)
s=s*i;
return s;
}
//递归 jiec ( n=3 ) = t=return jiec (n-1) *n; //=n!
int jiec (int n=3) //给我n得到 n!
{
if( n==1 )//先写出口
return 1;//直接返回1
else return jiec(n-1)*n;
}
主函数: jie (3)--> return jiec (2)*3=1*2*3
-->jiec(n=2) return=1*2
return jiec(1)*2=1*2
--->return 1;--回带
int main()
{
cout<<jie(5)<<endl;
return 0;
}
案例2:he(int n) =1+2+..n
//自杀表达式
He(n)=he(n-1)+n
int he(int n)
{ if(n==1) return 1;
Else return he(n-1)+n;
} //he(4)=
}

案例3:x(3)=x*x*x; mi(float x,int a) =x(a)
自杀的表达式
mi(x,a)=mi(x,a-1)*x;
float mi(float x, int a)
{
if(a==0)//远大理想
return 1;
else return mi(x,a-1)*x;
}
cout<<mi(3.5,2)<<endl;
案例4:求最大公约数-欧几里得算法
X=12 y=18
18 12
12 6
6 0
Y x%y
X=20 y=30
Y x%y
30 20
20 10
10 0
X=18 y=12
12 6
6 0
int gcd(int x,int y)
{ if(y==0) //如果后面的y=0返回前面的x
return x;
else return gcd(y,x%y);
}
int a,b,k;
cout<<"输入两个整数"<<endl;
cin>>a>>b;
k=gcd(a,b);
cout<<"最大公约数为 "<<
k<<"最小公倍数"<<(a*b)/k;
第二题 开灯(light.pas/c/cpp)
【问题描述】
有n盏灯,放在一排,从1到n依次顺序编号。有m个人也从1到m依次顺序编号。第1个人(1号)将灯全部关闭;第2个人(2号)将凡是2的倍数的灯打开;第3个人(3号)将凡是3的倍数的灯作相反处理(该灯如果是开的,则将它关闭;如果是关的,则将它打开);以后的人都和3号一样,将凡是自己编号倍数的灯作相反处理。试计算当第m个人操作后,哪几盏灯是亮的?
【输入格式】light.in
输入文件一行有两个数n和m。分别表示灯的数目和人的数目。(n,m均是小于32768的自然数,且n>=m)
【输出格式】light.out
输出文件在同一行输出亮着的灯的编号。没有灯亮输出“NO”。
【样例输入】
5 3
【样例输出】
2 3 4
关灯 flag=0, 开灯 flag=1;
关键点:n个灯,!每个灯都有标记,所以是:标记数组
int flag[33000];
i=2;k=k+2;
i=3;k=k+3;
...
i=m;k=k+m;总结为: k=k+i;
int n,m,i,k,flag[33000];//每个灯都要标记,所以用标记数组
cin>>n>>m;
//第一个人关闭所有的灯
for(i=1;i<=n;i++)
flag[i]=0;
for (i=2 ;i<=m; i++)//i表示人:从第2个人开始到最后一个人m
{
for( k=i;k<=n;k=k+i) // (k=2,3,m; k<=n; k=k+2,+3,+m) //k表示灯
if(flag[k]==0)//把灯做相反处理
flag[k]=1;
else flag[k]=0;
}
for(i=1;i<=n;i++) //i表示灯
if(flag[i]==1)
cout<<i<<" ";
输出结果是:22
---------------------------------------------------------------------------------------------------------------------------------------
二、递归的使用
函数被其他的函数或者主函数调用。
递归自杀式的,自己调用自己。
(同理,相同的道理)
- 递归出口,问题简单化,树立远大的理想。
- 调用自身的表达式(自杀的表达式)
- 有条件地降阶(向出口去逼近)
案例3:x(3)=x*x*x; mi(float x,int a) =x(a)
自杀的表达式
mi(x,a)=mi(x,a-1)*x;
float mi(float x, int a)
{
if(a==0)//远大理想
return 1;
else return mi(x,a-1)*x;
}
cout<<mi(3.5,2)<<endl;
案例4:求最大公约数-欧几里得算法
X=12 y=18
18 12
12 6
6 0
Y x%y
X=20 y=30
Y x%y
30 20
20 10
10 0
X=18 y=12
12 6
6 0
int gcd(int x,int y)
{ if(y==0) //如果后面的y=0返回前面的x
return x;
else return gcd(y,x%y);
}
int a,b,k;
cout<<"输入两个整数"<<endl;
cin>>a>>b;
k=gcd(a,b);
cout<<"最大公约数为 "<<
k<<"最小公倍数"<<(a*b)/k;
案例5:兔子1,1,2,3,5,8,13...输出第n个月的兔子数
int tu(int n)//给我n输出第n个月的兔子数
{
int t1=1,t2=1,t3;
for(i=3;i<=n;i++)
{
t3=t1+t2;
t1=t2;//第2个月做为新的第1个月
t2=t3;
}
return t3;
}
//自杀的表达式:tu(n)= tu(n-1)+tu(n-2)
int tu(int n)
{
if(n==1||n==2)
return 1;
else return tu(n-1)+tu(n-2);
}
int main() { cout<<tu(8)<<endl;
int x;
cin>>x;
cout<< tu(x)<<endl;
}
案例4:猴子吃桃子,已经第5天只有1个桃子,问一共有多少桃子,
每天吃的是前一天的一半还多吃了一个。
tao(n)得到第n天的桃子数
分析:出口:tao(5)=1
主函数:tao(1)
故:tao(n)=(tao(n+1)+1)*2;
tao(n=4)=2*(tao(5)+1)=4
int tao(int n)//给我n,给你第n天的桃子数-tao(1)
{
if(n==5)
return 1;
else return ( tao(n+1) + 1)*2;
//tao(4)=return ( tao(5)+1 )*2=4
}
//主函数 cout<<tao(1)<<endl;
作业4:汉诺塔问题;思想:把N块盘子分解成上面的N-1块盘子和第N块盘子(最大的一块),采用三步走战略。
第1步: 把上面的???块盘子由???(源盘)--???(过渡盘)----->???(目标盘)
2 把第???块盘子由???---->C
3 把???上面的???块盘子由???(源盘)---???(过渡盘)-- ----->???(目标
return 1;
->hannum(1)=1 *2+1
-->hannum(2)=3*2+1=7
hannum(n=4) return hannum(3)=7*2+1=15;

//move(2,'a','b','c');
//三个字符:起始盘a,中间的叫过渡盘b,目标盘c
int num;
void move(int n=1,char a='b',char b='a',char c='c')
{if(n==1) //递归出口,只有1块
{
num++;//搬1次
cout<<a<<"--->"<<c<<endl;//a-->b num=1
return ;
} //end if
else { //3步走
move(n-1,'a','c','b' );//同理:第1步把上面的n-1由a->b
cout<<a<<"->"<<c<<endl ;//第2步:把第n块由a->c
num++;//计搬次数
move(n-1,b,a,c);//第3步:同理把b上面的n-1由b-->c
}//end else
}
//主函数调用: move(x,'A','B','C');
//move(2,'a','b','c');
质因子分解:fenj(int n=12,int x=2)
情况1:n%x!=0,说明x不是n的因子,递归同理 fenj(n,x+1);去做
情况2:n%x==0,说明x是n的因子,那么 n=n/x; n=12/2=6;递归同理
fenjie(n,x);
递归出口: if(n==1)
#include<bits/stdc++.h>
using namespace std;
void fenj(int n,int x) //给我n和x=2,用最小的质数去分解
{
//递归先出口
if(n==1)
return ;//结束
if(n%x==0) //情况1:x
{
n=n/x;//把n变小 12=12/2=6; 2*2*
cout<<x;
if(n!=1) //否则 多输出一个*
cout<<"*";
fenj(n,x);//同理,继续递归(6,2); (3,1)
}//end if
else fenj(n,x+1);
//x不能整除n,同理继续分解 (n,x+1);
}
int main()
{ int x; cin>>x; cout<<x<<"=";
fenj(x,2);
return 0;
}
------------------------------------------------------------------------------------------------------------------------------------
望采纳



资深天翼
ε=(´ο`*)))唉,我个弱鸡帮不上忙!
但我知道,除了我外所有人是对的。
唯一贡献,别采纳!!


高级光能
一、Introduction
递归算法是一种直接或者间接调用自身函数或者方法的算法。递归算法的实质是把问题分解成规模缩小的同类问题的子问题,然后递归调用方法来表示问题的解。递归算法对解决一大类问题很有效,它可以使算法简洁和易于理解。递归算法,其实说白了,就是程序的自身调用。它表现在一段程序中往往会遇到调用自身的那样一种coding策略,这样我们就可以利用大道至简的思想,把一个大的复杂的问题层层转换为一个小的和原问题相似的问题来求解的这样一种策略。递归往往能给我们带来非常简洁非常直观的代码形势,从而使我们的编码大大简化,然而递归的思维确实和我们的常规思维相逆的,我们通常都是从上而下的思维问题, 而递归趋势从下往上的进行思维。这样我们就能看到我们会用很少的语句解决了非常大的问题,所以递归策略的最主要体现就是小的代码量解决了非常复杂的问题。
二、递归算法解决问题的特点
• 递归就是方法里调用自身。
• 在使用递增归策略时,必须有一个明确的递归结束条件,称为递归出口。
• 递归算法解题通常显得很简洁,但递归算法解题的运行效率较低。所以一般不提倡用递归算法设计程序。
• 在递归调用的过程当中系统为每一层的返回点、局部量等开辟了栈来存储。递归次数过多容易造成栈溢出等,所以一般不提倡用递归算法设计程序。
三、递归算法要求。递归算法所体现的“重复”一般有三个要求:
(1) 是每次调用在规模上都有所缩小(通常是减半);
(2) 是相邻两次重复之间有紧密的联系,前一次要为后一次做准备(通常前一次的输出就作为后一次的输入);
(3) 是在问题的规模极小时必须用直接给出解答而不再进行递归调用,因而每次递归调用都是有条件的(以规模未达到直接解答的大小为条件),无条件递归调用将会成为死循环而不能正常结束。
四、经典案例需要注意的是:本文的程序是基于C的基础上编写的
(1)计算阶乘是递归程序设计的一个经典示例。计算某个数的阶乘就是用那个数去乘包括 1 在内的所有比它小的数。例如,factorial(5) 等价于 54321,而 factorial(3) 等价于 321。阶乘的一个有趣特性是,某个数的阶乘等于起始数(starting number)乘以比它小一的数的阶乘。例如,factorial(5) 与 5 * factorial(4) 相同。您很可能会像这样编写阶乘函数:
int factorial(int n)
{
return n * factorial(n - 1);
}
(2)不过,这个函数的问题是,它会永远运行下去,因为它没有终止的地方。函数会连续不断地调用 factorial。 当计算到零时,没有条件来停止它,所以它会继续调用零和负数的阶乘。因此,我们的函数需要一个条件,告诉它何时停止。由于小于 1 的数的阶乘没有任何意义,所以我们在计算到数字 1 的时候停止,并返回 1 的阶乘(即 1)。因此,真正的递归函数类似于:
int factorial(int n)
{
if(n == 1)
return 1;
else
return n * factorial(n - 1);
}
可见,只要初始值大于零,这个函数就能够终止。停止的位置称为 基线条件(base case)。基线条件是递归程序的 最底层位置,在此位置时没有必要再进行操作,可以直接返回一个结果。所有递归程序都必须至少拥有一个基线条件,而且 必须确保它们最终会达到某个基线条件;否则,程序将永远运行下去,直到程序缺少内存或者栈空间。
五、斐波纳契数列
斐波纳契数列(Fibonacci Sequence),最开始用于描述兔子生长的数目时用上了这数列。从数学上,费波那契数列是以递归的方法来定义:这样斐波纳契数列的递归程序就可以非常清晰的写出来了:
int Fibonacci(int n)
{
if (n <= 1)
return n;
else
return Fibonacci(n-1) + Fibonacci(n-2);
}
六、递归程序的基本步骤每一个递归程序都遵循相同的基本步骤:
(1) 初始化算法。递归程序通常需要一个开始时使用的种子值(seed value)。要完成此任务,可以向函数传递参数,或者提供一个入口函数, 这个函数是非递归的,但可以为递归计算设置种子值。
(2) 检查要处理的当前值是否已经与基线条件相匹配。如果匹配,则进行处理并返回值。
(3) 使用更小的或更简单的子问题(或多个子问题)来重新定义答案。
(4) 对子问题运行算法。
(5) 将结果合并入答案的表达式。
(6) 返回结果。
七、使用归纳定义
(1)有时候,编写递归程序时难以获得更简单的子问题。 不过,使用 归纳定义的(inductively-defined)数据集 可以令子问题的获得更为简单。归纳定义的数据集是根据自身定义的数据结构 —— 这叫做归纳定义(inductive definition)。
(2)例如,链表就是根据其本身定义出来的。链表所包含的节点结构体由两部分构成:它所持有的数据,以及指向另一个节点结构体(或者是 NULL,结束链表)的指针。 由于节点结构体内部包含有一个指向节点结构体的指针,所以称之为是归纳定义的。
(3)使用归纳数据编写递归过程非常简单。注意,与我们的递归程序非常类似,链表的定义也包括一个基线条件 —— 在这里是 NULL 指针。 由于 NULL 指针会结束一个链表,所以我们也可以使用 NULL 指针条件作为基于链表的很多递归程序的基线条件。
举两个简单的例子:
A、让我们来看一些基于链表的递归函数示例。假定我们有一个数字列表,并且要将它们加起来。履行递归过程序列的每一个步骤,以确定它如何应用于我们的求和函数:
(1) **初始化算法**。这个算法的种子值是要处理的第一个节点,将它作为参数传递给函数。
(2) 检查**基线条件**。程序需要检查确认当前节点是否为 NULL 列表。如果是,则返回零,因为一个空列表的所有成员的和为零。
(3) **使用更简单的子问题重新定义答案**。我们可以将答案定义为当前节点的内容加上列表中其余部分的和。为了确定列表其余部分的和, 我们针对下一个节点来调用这个函数。
(4) **合并结果**。递归调用之后,我们将当前节点的值加到递归调用的结果上
这样我们就可以很简单的写出链表求和的递归程序,实例如下:
int sum_list(struct list_node *1)
{
if(1 == NULL)
return 0;
return 1.data + sum_list(1.next);
}
B、汉诺塔问题
汉诺塔(Hanoi Tower)问题也是一个经典的递归问题,该问题描述如下:
**汉诺塔问题:**古代有一个梵塔,塔内有三个座A、B、C,A座上有64个盘子,盘子大小不等,大的在下,小的在上(如图)。有一个和尚想把这64个盘子从A座移到B座,但每次只能允许移动一个盘子,并且在移动过程中,3个座上的盘子始终保持大盘在下,小盘在上。我们的移动盘子的步骤为:
• 如果只有 1 个盘子,则不需要利用B塔,直接将盘子从A移动到C。
• 如果有 2 个盘子,可以先将盘子1上的盘子2移动到B;将盘子1移动到C;将盘子2移动到C。这说明了:可以借助B将2个盘子从A移动到C,当然,也可以借助C将2个盘子从A移动到B。
• 如果有3个盘子,那么根据2个盘子的结论,可以借助c将盘子1上的两个盘子从A移动到B;将盘子1从A移动到C,A变成空座;借助A座,将B上的两个盘子移动到C。
以此类推,上述的思路可以一直扩展到 n 个盘子的情况,将将较小的 n-1个盘子看做一个整体,也就是我们要求的子问题,以借助B塔为例,可以借助空塔B将盘子A上面的 n-1 个盘子从A移动到B;将A最大的盘子移动到C,A变成空塔;借助空塔A,将B塔上的 n-2 个盘子移动到A,将B最大的盘子移动到C,B变成空塔…
void Hanoi (int n, char A, char B, char C)
{
if (n==1)
{ //end condition
move(A,B); //‘move’ can be defined to be a print function
}
else
{
Hanoi(n-1,A,C,B); //move sub [n-1] pans from A to B
move(A,C); //move the bottom(max) pan to C
Hanoi(n-1,B,A,C); //move sub [n-1] pans from B to C
}
}
八、将循环转化为递归
在下表中了解循环的特性,看它们可以如何与递归函数的特性相对比。
循环(Properties Loops)特性:
**重复**:为了获得结果,反复执行同一代码块;以完成代码块或者执行 continue 命令信号而实现重复执行。
**终止条件**:为了确保能够终止,循环必须要有一个或多个能够使其终止的条件,而且必须保证它能在某种情况下满足这些条件的其中之一。
**状态**:循环进行时更新当前状态。
递归函数特性:
**重复**:为了获得结果,反复执行同一代码块;以反复调用自己为信号而实现重复执行。
**终止条件**:为了确保能够终止,递归函数需要有一个基线条件,令函数停止递归。
**状态**:当前状态作为参数传递。
可见,递归函数与循环有很多类似之处。实际上,可以认为**循环和递归函数是能够相互转换的**。
区别在于,使用递归函数极少被迫修改任何一个变量 —— 只需要将新值作为参数传递给下一次函数调用。
这就使得您可以获得避免使用可更新变量的所有益处,同时能够进行重复的、有状态的行为。
下面还是以阶乘为例子,循环写法为:
int factorial(int n)
{
int product = 0;
while(n>0)
{
product *= n;
n--;
}
return product;
}
九、尾递归介绍
对于递归函数的使用,人们所关心的一个问题是栈空间的增长。确实,随着被调用次数的增加,某些种类的递归函数会线性地增加栈空间的使用 —— 不过,有一类函数,即尾部递归函数,不管递归有多深,栈的大小都保持不变。尾递归属于线性递归,更准确的说是线性递归的子集。
函数所做的最后一件事情是一个函数调用(递归的或者非递归的),这被称为 尾部调用(tail-call)。使用尾部调用的递归称为 尾部递归。当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活动记录而不是在栈中去创建一个新的。编译器可以做到这点,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。通过覆盖当前的栈帧而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。
让我们来看一些尾部调用和非尾部调用函数示例,以了解尾部调用的含义到底是什么:
int test1()
{
int a = 3;
test1(); /* recursive, but not a tail call. We continue */
/* processing in the function after it returns. */
a = a + 4;
return a;
}
int test2()
{
int q = 4;
q = q + 5;
return q + test1(); /* test1() is not in tail position.
* There is still more work to be
* done after test1() returns (like
* adding q to the result*/
}
int test3()
{
int b = 5;
b = b + 2;
return test1(); /* This is a tail-call. The return value
* of test1() is used as the return value
* for this function.*/
}
int test4()
{
test3(); /* not in tail position */
test3(); /* not in tail position */
return test3(); /* in tail position */
}
可见,要使调用成为真正的尾部调用,在尾部调用函数返回之前,对其结果 不能执行任何其他操作。注意,由于在函数中不再做任何事情,那个函数的实际的栈结构也就不需要了。惟一的问题是,很多程序设计语言和编译器不知道 如何除去没有用的栈结构。如果我们能找到一个除去这些不需要的栈结构的方法,那么我们的尾部递归函数就可以在固定大小的栈中运行。
在尾部调用之后除去栈结构的方法称为 尾部调用优化 。
(1)那么这种优化是什么?我们可以通过询问其他问题来回答那个问题:
(a) 函数在尾部被调用之后,还需要使用哪个本地变量?哪个也不需要。
(b) 会对返回的值进行什么处理?什么处理也没有。
(c) 传递到函数的哪个参数将会被使用?哪个都没有。
好像一旦控制权传递给了尾部调用的函数,栈中就再也没有有用的内容了。虽然还占据着空间,但函数的栈结构此时实际上已经没有用了,因此,尾部调用优化就是要在尾部进行函数调用时使用下一个栈结构 覆盖 当前的栈结构,同时保持原来的返回地址。我们所做的本质上是对栈进行处理。再也不需要活动记录(activation record),所以我们将删掉它,并将尾部调用的函数重定向返回到调用我们的函数。 这意味着我们必须手工重新编写栈来仿造一个返回地址,以使得尾部调用的函数能直接返回到调用它的函数。
**总结;**递归是一门伟大的艺术,使得程序的正确性更容易确认,而不需要牺牲性能,但这需要程序员以一种新的眼光来研究程序设计。对新程序员 来说,命令式程序设计通常是一个更为自然和直观的起点,这就是为什么大部分程序设计说明都集中关注命令式语言和方法的原因。 不过,随着程序越来越复杂,递归程序设计能够让程序员以可维护且逻辑一致的方式更好地组织代码。
求大佬采纳,没豆了


高级光能
1.概念
递归函数即自调用函数,在函数内部直接的或者间接地调用自己。在求解某些具有随意性的复杂问题时经常使用递归,如要求编写一个函数,将输入的任意长度的字符串反向输出。普通做法是将字符串放入数组中然后将数组元素反向输出即可,然而这里的要求是输入是任意长度的,总不能开辟一个很大的空间保存字符串吧?这时候递归就起作用了。递归采用了分治的思想,将整体分割成部分,从最小的基本部分入手,逐一解决,其中部分通常和整体具有相同的结构,这样部分可以继续分割,直到最后分割成基本部分。
递归函数必须定义一个终止条件,即什么情况下终止递归,终止继续调用自己,如果没有终止条件,那么函数将一直调用自己,知道程序栈耗尽,这时候等于是写了一个Bug!
总结递归的特点:
(1) 使用递归时,一定要有明确的终止条件!
(2) 递归算法解题通常代码比较简洁,但不是很容易读懂。
(3) 递归的调用需要建立大量的函数的副本,尤其是函数的参数,每一层递归调用时参数都是单独的占据内存空间,他们的地址是不同的,因此递归会消耗大量的时间和内存。而非递归函数虽然效率高,但相对比较难编程。
(4) 递归函数分为调用和回退阶段,递归的回退顺序是它调用顺序的逆序。


初级启示者
递归就是动态规划的前身,速度很慢


新手启示者
212121231231
