

高级光能
有很多同学一看到排序就懵逼。。。
今天,我来整理整理排序(结尾有对于蒟蒻(我)的彩蛋)
1 选择排序
框架:
for(int i=1;i<=n;i++){
for(int j=i+1;j<=n;j++){
if(a[i]<a[j]){//这里按照降序排列
swap(a[i],a[j]);//swap 交换函数
}
}
}
原理:

性能说明
时间复杂度:O(n^2)
空间复杂度:O(1)
非稳定的原地排序
2 快速排序
框架
#include<algorithm>
……
……
int a[1001];
…… {
int n;
scanf("&d",&n);
sort(a+1,a+1+n);
……
}
原理:难解释诶。。。OvO抱歉。。。
性能分析
时间复杂度:O(n*log(n))
空间复杂度:O(log(n))
非稳定的原地排序
3 冒泡排序
框架
for (int i = 1; i <= n; i++)
{
for (int j = 1; j < n - i - 1; j++)
{
if (p[j] > p[j + 1])
{
swap(p[j], p[j + 1]);
}
}
}
原理
性能分析
时间复杂度:O(n^2)
空间复杂度:O(1)
稳定的原地排序
4 桶排序
框架
int a[1001]{
int n,t;
cin>>n;
for(int i=1;i<=n;i++){
cin>>t;
a[t]++;
}
……
……if(a[i]??)……//根据实际情况考虑
}
原理

性能分析
时间复杂度:O(n+m)。
空间复杂度:O(n+m)
非稳定的非原地排序
李致远在2020-08-28 10:01:41追加了内容
十种常见排序算法可以分为两大类:
非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序。
线性时间非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。

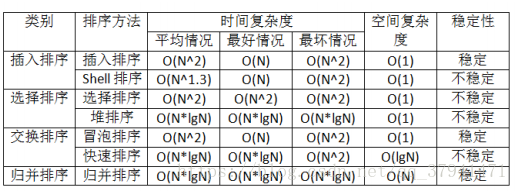
算法之间 时间复杂度.空间复杂度.稳定性的比较:

ps:希尔排序,当N大时,平均的时间复杂度,大约在N^1.25–1.6N^1.25之间。
概念分解:
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
今天只详解几种:
每种排序算法都各有优缺点。
影响排序的因素有很多,平均时间复杂度低的算法并不一定就是最优的。相反,有时平均时间复杂度高的算法可能更适合某些特殊情况。同时,选择算法时还得考虑它的可读性,以利于软件的维护。一般而言,需要考虑的因素有以下四点:
1.待排序的记录数目n的大小;
2.记录本身数据量的大小,也就是记录中除关键字外的其他信息量的大小;
3.关键字的结构及其分布情况;
4.对排序稳定性的要求。
设待排序元素的个数为n.
1)当n较大,则应采用时间复杂度为O(nlog2n)的排序方法:快速排序、堆排序或归并排序序。
快速排序:是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
堆排序 : 如果内存空间允许且要求稳定性的,
归并排序:它有一定数量的数据移动,所以我们可能过与插入排序组合,先获得一定长度的序列,然后再合并,在效率上将有所提高。
- 1
- 2
- 3
2) 当n较大,内存空间允许,且要求稳定性 ——归并排序
3)当n较小,可采用直接插入或直接选择排序。
直接插入排序:当元素分布有序,直接插入排序将大大减少比较次数和移动记录的次数。
直接选择排序 :元素分布有序,如果不要求稳定性,选择直接选择排序
- 1
- 2
5)一般不使用或不直接使用传统的冒泡排序。
6)基数排序
它是一种稳定的排序算法,但有一定的局限性:
1、关键字可分解。
2、记录的关键字位数较少,如果密集更好
3、如果是数字时,最好是无符号的,否则将增加相应的映射复杂度,可先将其正负分开排序。
直接排序:
直接插入排序
希尔排序
直接插入排序 :
思想:将数组中的所有元素依次和前面的已经排好序的元素相比较(依次),如果选择的元素比已排序的元素小,则交换,直到全部元素都比较过。

代码实现:
include <iostream>
using namespace std;
#include <assert.h>
//直接插入排序
void InsertSort (int* a,size_t n)
{
assert(a);
for(size_t i = 1;i < n; ++i)//用end的位置控制边界
{
//单趟排序
int end = i - 1 ;
int tmp = a[i];
while( end >= 0 )//循环继续条件
{
if( a[end] > tmp )
{
a[end+1] = a[end];
--end;
}
else
break;
}
a[end+1] = tmp;
}
}
希尔排序 :
思想:希尔排序也称缩小增量排序;希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序,随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时(用gap = gap/3+1 控制),保证了最后一次进行直接插入排序,算法终止。(其中直接插入排序是希尔排序gap=1的特例)另外,gap越大,值越大的容易到最后面,但是不太接近有序。—— 一般gap不要超过数组大小的一半

代码实现:
void ShellSort(int* a,size_t n)
{
assert(a);
//1. gap > 1 预排序
//2. gap == 1 直接插入排序
//3. gap = gap/3 + 1; 保证最后一次排序是直接插入排序
int gap = n;
while ( gap > 1 )
{
gap = gap/3+1;
//单趟排序
for(size_t i = 0;i < n-gap; ++i)
{
int end = i;
int tmp = a[end+gap];
while( end >= 0 && a[end] > tmp )
{
a[end+gap] = a[end];
end -= gap;
}
a[end+gap] = tmp;
}
}
}
选择排序:
选择排序
堆排序
选择排序:
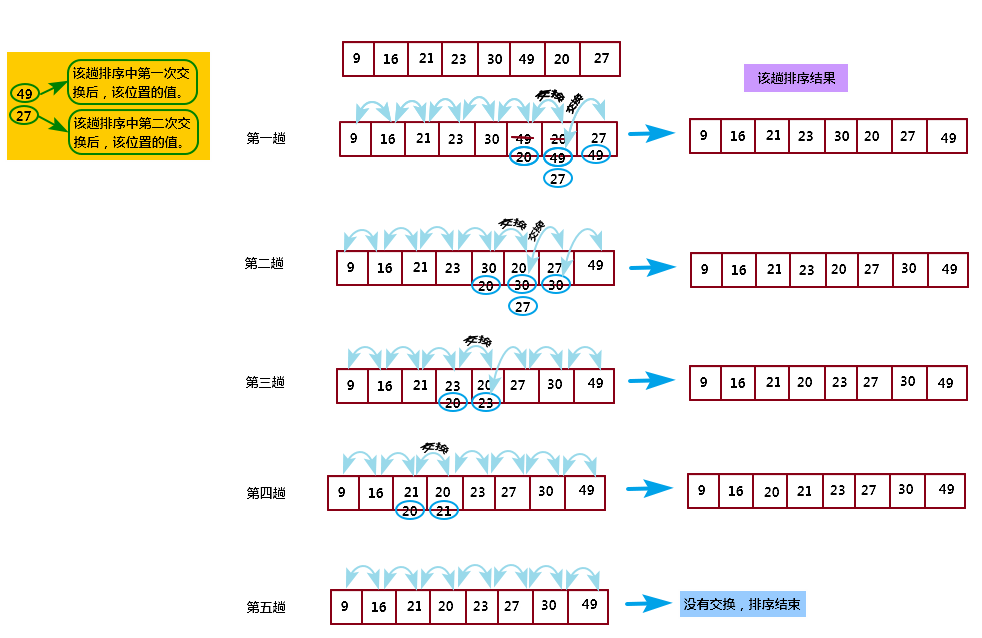
思想:在一个无序数组中选择出每一轮中最值元素,然后把这一轮中最前面的元素和min交换,最后面的元素和max交换;然后缩小范围(开始位置(begin++)++,最后位置(end–)–),重复上面步骤,最终得到有序序列(升序)。
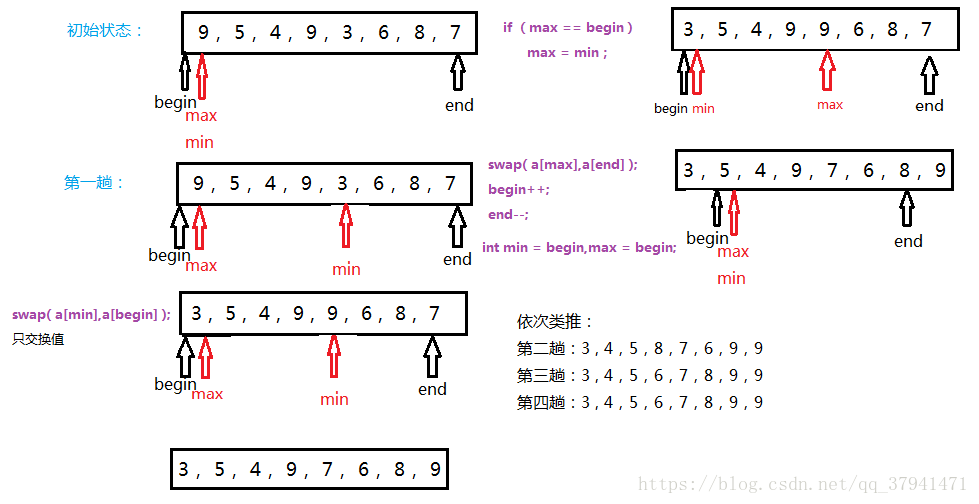
代码实现:
void SelectSort(int* a,size_t n)
{
assert(a);
int begin = 0;
int end = n-1;
while ( begin < end )
{
int min = begin,max = begin;
for(int i = begin; i <= end; ++i)
{
if( a[min] > a[i] )
min = i;
if( a[max] < a[i] )
max = i;
}
swap( a[min],a[begin] );
if( max == begin )//如果首元素是最大的,则需要先把min 和 max的位置一换,再交换,否则经过两次交换,又回到原来的位置
max = min;
swap( a[max],a[end] );
begin++;
end--;
}
}
堆排序 :
思想:
堆排序利用了大堆(或小堆)堆顶记录的关键字最大(或最小)这一特征,使得当前无序的序列中选择关键最大(或最小)的记录变得简单。(升序—建大堆,降序—建小堆)
代码实现:
class HeapSort {
public:
void AdjustDown(int *A, int root, int n){
int parent = root;
int child = parent*2+1; // 左孩子
while( child < n ){
if( (child+1) < n && A[child+1] > A[child] ){
++child;
}
if( A[child] > A[parent] ){
swap(A[child],A[parent]);
parent = child;
child = parent*2+1;
}
else
break;
}
}
int* heapSort(int* A, int n) {
// write code here
assert(A);
// 找到倒数第一个非叶子节点----- 建大堆
for( int i = (n-2)/2; i >=0 ; i-- ){
AdjustDown(A,i,n);
}
int end = n-1;
while( end > 0 ){
swap(A[0],A[end]);
AdjustDown(A,0,end); // end其实就是不算后面的一个元素,原因是最后一个节点已经是最大的
end--;
}
return A;
}
};
交换排序
冒泡排序
快速排序
冒泡排序:
基本思想就是:从无序序列头部开始,进行两两比较,根据大小交换位置,直到最后将最大(小)的数据元素交换到了无序队列的队尾,从而成为有序序列的一部分;下一次继续这个过程,直到所有数据元素都排好序。
算法的核心在于每次通过两两比较交换位置,选出剩余无序序列里最大(小)的数据元素放到队尾。
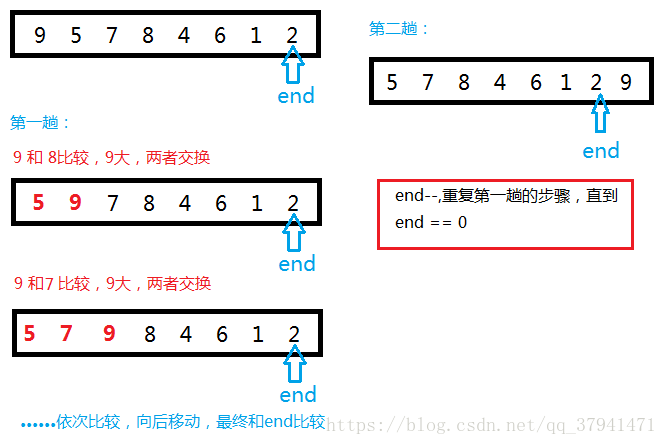
代码实现:
void BubbleSort(int* a,size_t n)
{
assert(a);
size_t end = n;
int exchange = 0;
while( end > 0 )//end作为每趟排序的终止条件
{
for( size_t i = 1; i < end ; ++i )
{
if( a[i-1] > a[i] )
{
swap(a[i-1],a[i]);
exchange = 1;
}
}
if( 0 == exchange )//数组本身为升序,如果一趟排序结束,并没有进行交换,那么直接跳出循环(减少循环次数,升高效率)
break;
--end;
}
}
快速排序:
详情见如下网址:这个
归并排序:
思想:分治法
每个递归过程涉及三个步骤
第一, 分解: 把待排序的 n 个元素的序列分解成两个子序列, 每个子序列包括 n/2 个元素.
第二, 治理: 对每个子序列分别调用归并排序__MergeSort, 进行递归操作
第三, 合并: 合并两个排好序的子序列,生成排序结果.
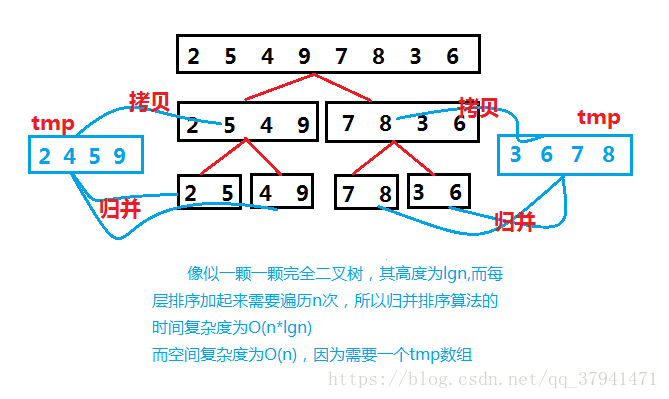
代码:
void __MergeSort( int *a, int left, int right, int * tmp )
{
if( left >= right ) //退出条件
return;
int mid = left+((right-left)>>1);
__MergeSort(a,left,mid,tmp); // 递归左半数组
__MergeSort(a,mid+1,right,tmp); // 递归右半数组
//将排好序的两部分数组归并(排序)
int begin1 = left,end1 = mid;
int begin2 = mid+1,end2 = right;
int index = left;
while( begin1<=end1 && begin2<=end2 )// 循环条件:任一个数组排序完,则终止条件,最后将没有比较完的数组直接一一拷过去
{
if( a[begin1] <= a[begin2] )
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while( begin1 <= end1 )//右半数组走完了
{
tmp[index++] = a[begin1++];
}
while( begin2 <= end2 )//左半数组走完了
{
tmp[index++] = a[begin2++];
}
//tmp数组已经排好序,将数组内容拷到原数组,递归向上一层走
index = left;
while( index <= right )
{
a[index] = tmp[index];
++index;
}
}
void MergeSort( int *a,size_t n )
{
int *tmp = new int[n]; // 开一个第三方数组来存取左右排好序归并后的序列
__MergeSort(a,0,n-1,tmp);
delete[] tmp; // 最后释放第三方空间
}
优化:
在递归子问题的时候在区间内的数据比较少的时候我们可以不再划分区间,直接用直接插入排序效率会更高,因为接着划分又要创建栈桢,没有必要
void __MergeSort( int *a, int left, int right, int * tmp )
{
if( left >= right ) //退出条件
return;
if( right-left+1 <10 )//优化
{
InsertSort(a+left,right-left+1);
}
int mid = left+((right-left)>>1);
__MergeSort(a,left,mid,tmp); // 递归左半数组
__MergeSort(a,mid+1,right,tmp); // 递归右半数组
//将排好序的两部分数组归并(排序)
int begin1 = left,end1 = mid;
int begin2 = mid+1,end2 = right;
int index = left;
while( begin1<=end1 && begin2<=end2 )// 循环条件:任一个数组排序完,则终止条件,最后将没有比较完的数组直接一一拷过去
{
if( a[begin1] <= a[begin2] )
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while( begin1 <= end1 )//右半数组走完了
{
tmp[index++] = a[begin1++];
}
while( begin2 <= end2 )//左半数组走完了
{
tmp[index++] = a[begin2++];
}
//tmp数组已经排好序,将数组内容拷到原数组,递归向上一层走
index = left;
while( index <= right )
{
a[index] = tmp[index];
++index;
}
}
void MergeSort( int *a,size_t n )
{
int *tmp = new int[n]; // 开一个第三方数组来存取左右排好序归并后的序列
__MergeSort(a,0,n-1,tmp);
delete[] tmp; // 最后释放第三方空间
}
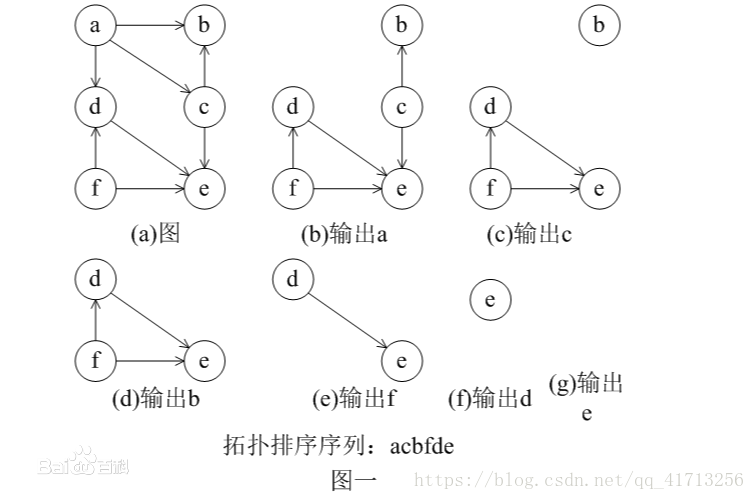
还有hzy大佬说的拓扑排序,图论的算法,有些难度,就当补充:
在一个有向图中,对所有的节点进行排序,要求没有一个节点指向它前面的节点。
先统计所有节点的入度,对于入度为0的节点就可以分离出来,然后把这个节点指向的节点的入度减一。
一直做改操作,直到所有的节点都被分离出来。
如果最后不存在入度为0的节点,那就说明有环,不存在拓扑排序,也就是很多题目的无解的情况。
下面是算法的演示过程:
代码:
queue<int>q;
vector<int>edge[n];
for(int i=0;i<n;i++) //n 节点的总数
if(in[i]==0) q.push(i); //将入度为0的点入队列
vector<int>ans; //ans 为拓扑序列
while(!q.empty())
{
int p=q.front(); q.pop(); // 选一个入度为0的点,出队列
ans.push_back(p);
for(int i=0;i<edge[p].size();i++)
{
int y=edge[p][i];
in[y]--;
if(in[y]==0)
q.push(y);
}
}
if(ans.size()==n)
{
for(int i=0;i<ans.size();i++)
printf( "%d ",ans[i] );
printf("\n");
}
else printf("No Answer!\n"); // ans 中的长度与n不相等,就说明无拓扑序列
有些拓扑排序要求字典序最小什么的,那就把队列换成优先队列就好了。
注 以上摘自王子健大佬//其实我懒得更新了
李致远在2020-08-28 15:19:49追加了内容
刚刚看了一下,好像没有没讲过的了。
彩蛋(再次强调,是对于像我一样的蒟蒻的彩蛋,大佬勿喷):搜索与回溯+递推↓
1 搜索与回溯
搜索与回溯是计算机解题中常用的算法,很多问题无法根据
某种确定的计算法则来求解,可以利用搜索与回溯的技术求解。
回溯是搜索算法中的一种控制策略。它的基本思想是:为了求得
问题的解,先选择某一种可能情况向前探索,在探索过程中,一
旦发现原来的选择是错误的,就退回一步重新选择,继续向前探
索,如此反复进行,直至得到解或证明无解。
如迷宫问题:进入迷宫后,先随意选择一个前进方向,一步
步向前试探前进,如果碰到死胡同,说明前进方向已无路可走,
这时,首先看其它方向是否还有路可走,如果有路可走,则沿该
方向再向前试探;如果已无路可走,则返回一步,再看其它方向
是否还有路可走;如果有路可走,则沿该方向再向前试探。按此
原则不断搜索回溯再搜索,直到找到新的出路或从原路返回入口
处无解为止。
递归回溯法算法框架[一]
int Search(int k)
{
for (i=1;i<=算符种数;i++)
if (满足条件)
{
保存结果
if (到目的地) 输出解;
else Search(k+1);
恢复:保存结果之前的状态{回溯一步}
}
}
递归回溯法算法框架[二]
int Search(int k)
{
if (到目的地) 输出解;
else
for (i=1;i<=算符种数;i++)
if (满足条件)
{
保存结果;
Search(k+1);
恢复:保存结果之前的状态{回溯一步}
}
李致远在2020-08-28 20:03:52追加了内容
2 递推
基本介绍
递推是按照一定的规律来计算序列中的每个项,通常是通过计算前面的一些项来得出序列中的指定项的值。其思想是把一个复杂的庞大的计算过程转化为简单过程的多次重复,该算法利用了计算机速度快和不知疲倦的机器特点。//摘自百度
例题1 输入n,请你求出斐波那契数列第n项(n<=15)
大家都知道斐波那契数列的当前项等于前两项之和。
那么我们的code的递推公式则是:f[n]=f[n-1]+f[n-2];//顺便提一下,一般我们习惯将递推的数组定义为f
辣么这样对不对嘞?
很抱歉,不对!
Why?
灵魂拷问:当循环变量i==1||i==2是肿么办?
难不成f[1]=f[0]+f[-1],f[2]=f[1]+f[0]???(←泥垢了)
————————————————
所以我们要判断特殊情况,即边界条件!
那么此题的边界条件即为:f[1]=f[2]=1;
然后即可AC!
例题2 给定一个正整数n,求n!(n<=15)
解析:
 (有更好的解法请指出,大佬勿喷)
(有更好的解法请指出,大佬勿喷)
那么边界条件呢?
我们发现递推公式中有f[n-1]
所以我们要设置f[1]=1;
即可AC!
————————————————
这里讲一个注意事项:
你的循环初值是你的最大边界条件的下标+1!
————————————————
例题3 最短时间
卡卡西开心的离开了学校。现在她想骑车回家(注 卡卡西已达到骑车要求)
她发现自己回家路上有很多条路都很堵。于是她给出了每条路通过时间,请你求出她回家的最短时间。
解析:
这道题类似于DP(好吧,你可以说它就是DP)。
我们的思路是:因为卡卡西想最快回家,所以她只能向上或想右走。
那么我们双重循环,每次取这两个的最小值即可。
即:f[i][j]==max(f[i][j+1],f[i-1][j]);
作业 最短时间(min.cpp)
要求:
1 使用文件操作
2 代码加上注释
3 主要方法用递归(或DP,搜索与回溯)
奖励:
最先做出作业的前3位将加入采纳名单(后续我可能会把豆豆+到100)
目前采纳名单:
1 王子健
题目:
卡卡西回到家,开始做作业。有一道题把她难住了。于是她来请教你。
现在有一个n*m的矩阵。
矩阵的每个坐标点会给出通过得分
但是有些边上会有陷阱。而卡卡西共有t滴血(0<t<=3)
每个陷阱碰到会扣一滴血。
卡卡西没血了就失败了。
注 卡卡西在最后必须得从出口出来,否则得分清零。而且卡卡西只能向以入口为参照物的上和右
卡卡西懵逼了。。。
于是,她来请教你。
输入描述
第一行输入n,m,表示n*m的矩阵。
接下来输入这个矩阵,四个角会有两个为0,表示出口和入口(注 出口入口自己选择,且保证入口出口在左下和右上)
再输入一个g(0<=g<=t<3),表示陷阱数量
接下来,输入g个(n1,m1),表示陷阱坐标
在输入t,表示卡卡西的血量。
输出描述
输出卡卡西可得到的最大分数及其剩余血量(空格隔开)
输入样例(样例贼水哈):
5 5
1 3 2 5 0
2 4 3 5 7
1 2 8 6 4
3 3 7 9 1
0 2 3 5 4
0
1
输出样例:
40
提示
我是不会告诉你入口出口得分一样的!


初级天翼
既然你说浅谈一下,那我也来浅谈一下吧,也为你在此讲解一下归并:
十种常见排序算法可以分为两大类:
非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序。
线性时间非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。
算法之间 时间复杂度.空间复杂度.稳定性的比较:
ps:希尔排序,当N大时,平均的时间复杂度,大约在N^1.25–1.6N^1.25之间。
概念分解:
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
今天只详解几种:
每种排序算法都各有优缺点。
影响排序的因素有很多,平均时间复杂度低的算法并不一定就是最优的。相反,有时平均时间复杂度高的算法可能更适合某些特殊情况。同时,选择算法时还得考虑它的可读性,以利于软件的维护。一般而言,需要考虑的因素有以下四点:
1.待排序的记录数目n的大小;
2.记录本身数据量的大小,也就是记录中除关键字外的其他信息量的大小;
3.关键字的结构及其分布情况;
4.对排序稳定性的要求。
设待排序元素的个数为n.
1)当n较大,则应采用时间复杂度为O(nlog2n)的排序方法:快速排序、堆排序或归并排序序。
快速排序:是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
堆排序 : 如果内存空间允许且要求稳定性的,
归并排序:它有一定数量的数据移动,所以我们可能过与插入排序组合,先获得一定长度的序列,然后再合并,在效率上将有所提高。
- 1
- 2
- 3
2) 当n较大,内存空间允许,且要求稳定性 ——归并排序
3)当n较小,可采用直接插入或直接选择排序。
直接插入排序:当元素分布有序,直接插入排序将大大减少比较次数和移动记录的次数。
直接选择排序 :元素分布有序,如果不要求稳定性,选择直接选择排序
- 1
- 2
5)一般不使用或不直接使用传统的冒泡排序。
6)基数排序
它是一种稳定的排序算法,但有一定的局限性:
1、关键字可分解。
2、记录的关键字位数较少,如果密集更好
3、如果是数字时,最好是无符号的,否则将增加相应的映射复杂度,可先将其正负分开排序。
直接排序:
直接插入排序
希尔排序
直接插入排序 :
思想:将数组中的所有元素依次和前面的已经排好序的元素相比较(依次),如果选择的元素比已排序的元素小,则交换,直到全部元素都比较过。
代码实现:
include <iostream>
using namespace std;
#include <assert.h>
//直接插入排序
void InsertSort (int* a,size_t n)
{
assert(a);
for(size_t i = 1;i < n; ++i)//用end的位置控制边界
{
//单趟排序
int end = i - 1 ;
int tmp = a[i];
while( end >= 0 )//循环继续条件
{
if( a[end] > tmp )
{
a[end+1] = a[end];
--end;
}
else
break;
}
a[end+1] = tmp;
}
}
希尔排序 :
思想:希尔排序也称缩小增量排序;希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序,随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时(用gap = gap/3+1 控制),保证了最后一次进行直接插入排序,算法终止。(其中直接插入排序是希尔排序gap=1的特例)另外,gap越大,值越大的容易到最后面,但是不太接近有序。—— 一般gap不要超过数组大小的一半
代码实现:
void ShellSort(int* a,size_t n)
{
assert(a);
//1. gap > 1 预排序
//2. gap == 1 直接插入排序
//3. gap = gap/3 + 1; 保证最后一次排序是直接插入排序
int gap = n;
while ( gap > 1 )
{
gap = gap/3+1;
//单趟排序
for(size_t i = 0;i < n-gap; ++i)
{
int end = i;
int tmp = a[end+gap];
while( end >= 0 && a[end] > tmp )
{
a[end+gap] = a[end];
end -= gap;
}
a[end+gap] = tmp;
}
}
}
选择排序:
选择排序
堆排序
选择排序:
思想:在一个无序数组中选择出每一轮中最值元素,然后把这一轮中最前面的元素和min交换,最后面的元素和max交换;然后缩小范围(开始位置(begin++)++,最后位置(end–)–),重复上面步骤,最终得到有序序列(升序)。
代码实现:
void SelectSort(int* a,size_t n)
{
assert(a);
int begin = 0;
int end = n-1;
while ( begin < end )
{
int min = begin,max = begin;
for(int i = begin; i <= end; ++i)
{
if( a[min] > a[i] )
min = i;
if( a[max] < a[i] )
max = i;
}
swap( a[min],a[begin] );
if( max == begin )//如果首元素是最大的,则需要先把min 和 max的位置一换,再交换,否则经过两次交换,又回到原来的位置
max = min;
swap( a[max],a[end] );
begin++;
end--;
}
}
堆排序 :
思想:
堆排序利用了大堆(或小堆)堆顶记录的关键字最大(或最小)这一特征,使得当前无序的序列中选择关键最大(或最小)的记录变得简单。(升序—建大堆,降序—建小堆)
代码实现:
class HeapSort {
public:
void AdjustDown(int *A, int root, int n){
int parent = root;
int child = parent*2+1; // 左孩子
while( child < n ){
if( (child+1) < n && A[child+1] > A[child] ){
++child;
}
if( A[child] > A[parent] ){
swap(A[child],A[parent]);
parent = child;
child = parent*2+1;
}
else
break;
}
}
int* heapSort(int* A, int n) {
// write code here
assert(A);
// 找到倒数第一个非叶子节点----- 建大堆
for( int i = (n-2)/2; i >=0 ; i-- ){
AdjustDown(A,i,n);
}
int end = n-1;
while( end > 0 ){
swap(A[0],A[end]);
AdjustDown(A,0,end); // end其实就是不算后面的一个元素,原因是最后一个节点已经是最大的
end--;
}
return A;
}
};
交换排序
冒泡排序
快速排序
冒泡排序:
基本思想就是:从无序序列头部开始,进行两两比较,根据大小交换位置,直到最后将最大(小)的数据元素交换到了无序队列的队尾,从而成为有序序列的一部分;下一次继续这个过程,直到所有数据元素都排好序。
算法的核心在于每次通过两两比较交换位置,选出剩余无序序列里最大(小)的数据元素放到队尾。
代码实现:
void BubbleSort(int* a,size_t n)
{
assert(a);
size_t end = n;
int exchange = 0;
while( end > 0 )//end作为每趟排序的终止条件
{
for( size_t i = 1; i < end ; ++i )
{
if( a[i-1] > a[i] )
{
swap(a[i-1],a[i]);
exchange = 1;
}
}
if( 0 == exchange )//数组本身为升序,如果一趟排序结束,并没有进行交换,那么直接跳出循环(减少循环次数,升高效率)
break;
--end;
}
}
快速排序:
详情见如下网址:这个
归并排序:
思想:分治法
每个递归过程涉及三个步骤
第一, 分解: 把待排序的 n 个元素的序列分解成两个子序列, 每个子序列包括 n/2 个元素.
第二, 治理: 对每个子序列分别调用归并排序__MergeSort, 进行递归操作
第三, 合并: 合并两个排好序的子序列,生成排序结果.
代码:
void __MergeSort( int *a, int left, int right, int * tmp )
{
if( left >= right ) //退出条件
return;
int mid = left+((right-left)>>1);
__MergeSort(a,left,mid,tmp); // 递归左半数组
__MergeSort(a,mid+1,right,tmp); // 递归右半数组
//将排好序的两部分数组归并(排序)
int begin1 = left,end1 = mid;
int begin2 = mid+1,end2 = right;
int index = left;
while( begin1<=end1 && begin2<=end2 )// 循环条件:任一个数组排序完,则终止条件,最后将没有比较完的数组直接一一拷过去
{
if( a[begin1] <= a[begin2] )
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while( begin1 <= end1 )//右半数组走完了
{
tmp[index++] = a[begin1++];
}
while( begin2 <= end2 )//左半数组走完了
{
tmp[index++] = a[begin2++];
}
//tmp数组已经排好序,将数组内容拷到原数组,递归向上一层走
index = left;
while( index <= right )
{
a[index] = tmp[index];
++index;
}
}
void MergeSort( int *a,size_t n )
{
int *tmp = new int[n]; // 开一个第三方数组来存取左右排好序归并后的序列
__MergeSort(a,0,n-1,tmp);
delete[] tmp; // 最后释放第三方空间
}
优化:
在递归子问题的时候在区间内的数据比较少的时候我们可以不再划分区间,直接用直接插入排序效率会更高,因为接着划分又要创建栈桢,没有必要
void __MergeSort( int *a, int left, int right, int * tmp )
{
if( left >= right ) //退出条件
return;
if( right-left+1 <10 )//优化
{
InsertSort(a+left,right-left+1);
}
int mid = left+((right-left)>>1);
__MergeSort(a,left,mid,tmp); // 递归左半数组
__MergeSort(a,mid+1,right,tmp); // 递归右半数组
//将排好序的两部分数组归并(排序)
int begin1 = left,end1 = mid;
int begin2 = mid+1,end2 = right;
int index = left;
while( begin1<=end1 && begin2<=end2 )// 循环条件:任一个数组排序完,则终止条件,最后将没有比较完的数组直接一一拷过去
{
if( a[begin1] <= a[begin2] )
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while( begin1 <= end1 )//右半数组走完了
{
tmp[index++] = a[begin1++];
}
while( begin2 <= end2 )//左半数组走完了
{
tmp[index++] = a[begin2++];
}
//tmp数组已经排好序,将数组内容拷到原数组,递归向上一层走
index = left;
while( index <= right )
{
a[index] = tmp[index];
++index;
}
}
void MergeSort( int *a,size_t n )
{
int *tmp = new int[n]; // 开一个第三方数组来存取左右排好序归并后的序列
__MergeSort(a,0,n-1,tmp);
delete[] tmp; // 最后释放第三方空间
}
还有hzy大佬说的拓扑排序,图论的算法,有些难度,就当补充:
在一个有向图中,对所有的节点进行排序,要求没有一个节点指向它前面的节点。
先统计所有节点的入度,对于入度为0的节点就可以分离出来,然后把这个节点指向的节点的入度减一。
一直做改操作,直到所有的节点都被分离出来。
如果最后不存在入度为0的节点,那就说明有环,不存在拓扑排序,也就是很多题目的无解的情况。
下面是算法的演示过程:
代码:
queue<int>q;
vector<int>edge[n];
for(int i=0;i<n;i++) //n 节点的总数
if(in[i]==0) q.push(i); //将入度为0的点入队列
vector<int>ans; //ans 为拓扑序列
while(!q.empty())
{
int p=q.front(); q.pop(); // 选一个入度为0的点,出队列
ans.push_back(p);
for(int i=0;i<edge[p].size();i++)
{
int y=edge[p][i];
in[y]--;
if(in[y]==0)
q.push(y);
}
}
if(ans.size()==n)
{
for(int i=0;i<ans.size();i++)
printf( "%d ",ans[i] );
printf("\n");
}
else printf("No Answer!\n"); // ans 中的长度与n不相等,就说明无拓扑序列
有些拓扑排序要求字典序最小什么的,那就把队列换成优先队列就好了。
注:其中有些高难度的内容是借鉴的,我没有hzy那么强大~
王子健在2020-08-28 08:08:36追加了内容
刚刚的图片有误,重新上传:


新手光能
我爱sort
高级光能
剩余的明天再更新

初级天翼
。。az,都好喜欢当算法普及导师啊!
我来扮演一下两年前的zyf 大佬:
来来来,说一下归并排序(J6还是J7,但分治也没有那么难吧,我会背/xyx(指归并排序和快速幂,别的分治当我没说(大雾)和拓扑排序(DAG,zyf 大佬两年前貌似把这个当成数值排序了,/xk,但还是要膜拜,两年前我还布吉岛这个名词)!
黄子扬在2020-08-28 00:16:30追加了内容
是zyf提问


中级天翼
哦,谢谢,(其实我也不怎么会排序)
你这个头像......
怎么做的


缔造者之神
排序用sort不错
初级天翼
你学过搜索?


初级启示者
qsort:我寻思我怎么这么没人气呢。。。为啥都把STL_sort叫做快速排序呢?难道我就不够快吗?我可是二分的衍生算法啊!


初级光能
顶

高级光能
orz
